

Quando falamos de publicidade, é muito relevante saber quantas pessoas serão atingidas pelo anúncio, principalmente para garantir que o investimento feito será revertido em lucro. Não é a toa que um anúncio de 30 segundos no intervalo do Super Bowl pode custar cerca de US$ 5,6 milhões (fonte). Quanto mais pessoas veem a propaganda, maior será a quantidade de pessoas que irá aderir ao produto que está sendo anunciado.

Nesse texto, exploraremos esse tema pensando no contexto fictício (que poderia ser real!) de uma empresa de aluguel de bicicletas, que está planejando implementar em suas estações um painel eletrônico, com informações de tempo e trânsito, que também terá espaços para anúncios. Nosso objetivo será descobrir quais são as estações e horários mais movimentados, para que a empresa consiga planejar a instalação dos painéis de forma mais rentável possível e, também, ter uma diretriz de preços para vender o espaço publicitário de acordo com o horário do dia.
Para isso, trabalharemos com uma base de dados sobre compartilhamento de bicicletas em Austin e aplicaremos conhecimentos de machine learning e análise de dados, em Python, para conhecer e prever o movimento nas estações.
Nessa base, temos os dados das estações de bicicleta (como localização, nome, id e se está ativa ou não) e, também, os dados das viagens feitas (como duração, estação de início e de chegada). Então, iremos criar uma solução que aprende com as informações de viagens antigas e, com isso, consegue indicar como será o movimento das estações nos próximos meses.
Tratando e analisando os dados
Antes de começar o projeto de machine learning, precisamos analisar e tratar nossa base de dados. Abrindo os arquivos em algum editor de dados, como o Excel, podemos fazer alguns comentários:
- Na base com os dados das viagens, os campos ‘start_station_id’ e ‘end_station_id’ possuem uma casa decimal desnecessária;
- Existem linhas com valores vazios para ‘start_station_id’ e ‘end_station_id’;
- Existem estações inativas (status ‘closed’) e que mudaram de lugar (status ‘moved’);
- Como iremos prever o movimento de cada estação, existem campos que não nos interessam. Utilizaremos apenas ‘end_station_id’, ‘start_station_id’, ‘start_time’ e ‘end_time’.
Então vamos resolver esses problemas! Utilizando Python, conseguimos tratar nossa base de dados:
Com isso, conseguimos montar uma base mais compacta, com os dados que nos interessam:
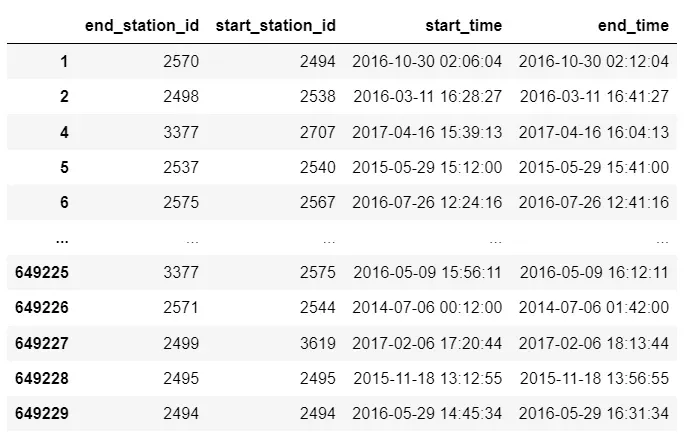
No entanto, como queremos analisar as movimentações nas estações, ainda podemos melhorar essa modelagem. Então, criaremos um dataframe com foco nas movimentações.
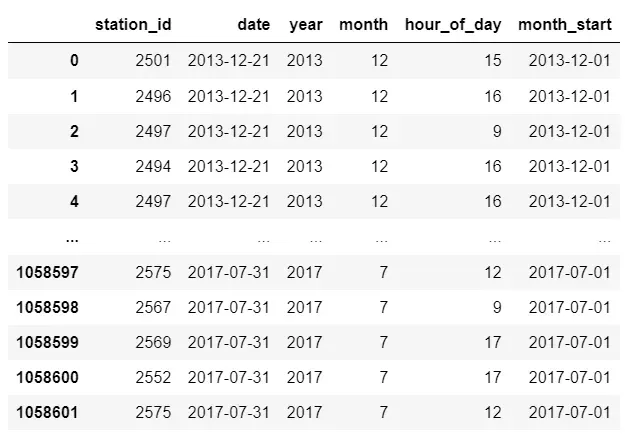
Finalmente, temos um modelo de dados adequado para o que precisamos. Agora, podemos gerar alguns gráficos para analisar os dados e tirar conclusões sobre os aluguéis de bicicleta.
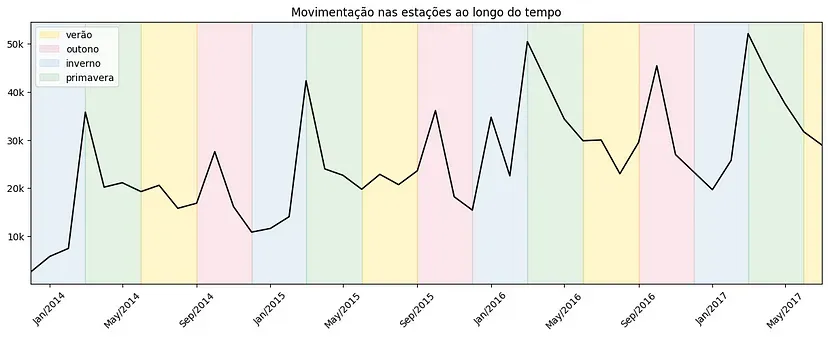
A partir da visão temporal das movimentações, conseguimos identificar quando ocorre um crescimento na quantidade de aluguéis. Também conseguimos perceber que a movimentação das estações tem aumentado ao longo dos anos.
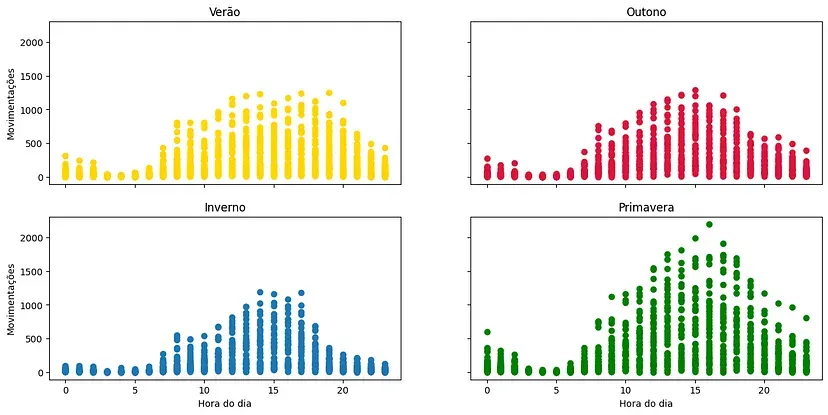
Com esses gráficos de dispersão, podemos ver, claramente, que a movimentação se concentra nos horários da tarde e começo da noite. Também vemos que a primavera é a estação do ano na qual ocorrem mais movimentações.
Com essa visão, já conseguimos criar uma diretriz de quanto cobrar pelo espaço publicitário de acordo com a hora do dia.
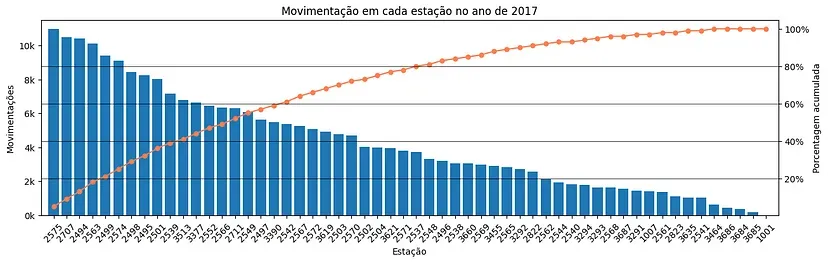
Nesse último gráfico, conseguimos identificar as estações que concentram determinadas porcentagens do total de movimentações. Podemos ver, por exemplo, que as estações de ID 2575, 2707, 2494 e 2563 concentram quase 20% da movimentação total.
Essa análise é importante para notarmos as estações mais movimentadas e, assim, planejarmos a instalação dos painéis de forma estratégica. Como 80% do movimento está concentrado em aproximadamente metade das estações, talvez não faça sentido instalar os painéis na outra metade, visto que a contribuição delas é pouca.
Prevendo a movimentação nos próximos meses
Agora que já exploramos a base de dados, podemos utilizar os dados para prever qual vai ser a movimentação de aluguéis nos próximos meses.
Como vimos pelas análises gráficas que a quantidade de movimentos é bastante influenciada pela data, estação do ano e ponto de aluguel, utilizaremos como features do nosso modelo os campos ‘station_id’, ‘month_start’, ‘month’ e ‘season’.
Agora que temos a base completa, ainda precisamos separar os dados de treino e de teste. Utilizaremos como treino os dados anteriores a 2017 e testaremos o modelo com os dados deste ano.
train = db.query("year != 2017").drop(columns='year')
X_train = train.drop(columns='count')
y_train = train['count']
test = db.query("year == 2017").drop(columns='year')
X_test = test.drop(columns='count')
y_test = test['count']Para fazer a previsão de movimentações, utilizaremos a biblioteca scikit-learn, muito utilizada em projetos de machine learning. No nosso caso, faremos a modelagem com o método RandomForestRegressor() . Esse algoritmo possui vários hiperparâmetros que podem ser sintonizados para obter um melhor desempenho. Em nosso caso, o único que iremos declarar será o n_estimators (número de árvores), com valor 100.
from sklearn.ensemble import RandomForestRegressor
import sklearn.metrics as metrics
rf = RandomForestRegressor(n_estimators=100)
rf.fit(X_train,y_train)
pred = np.rint(rf.predict(X_test))Simples assim, criamos a nossa previsão da movimentação! Podemos ver o resultado no gráfico a seguir.
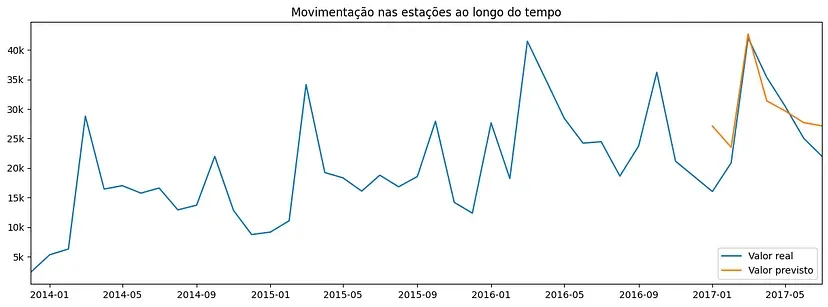
Com as métricas do sklearn, podemos avaliar o desempenho do nosso modelo de forma numérica:
MAE: 191.95
MAPE: 26.16%
r2 score: 0.72
O MAE (Mean Absolute Error) indica uma média para todos os registros do erro entre o valor previsto e o valor real. O MAPE (Mean Absolute Percentage Error) tem um significado parecido, indicando a média para todos os registros da razão entre o erro e o valor real. Já o r² score indica a correlação entre os valores previsto e real (quanto mais perto de 1, maior a correlação).
Como estamos tratando de uma série temporal, poderíamos obter resultados melhores utilizando técnicas de predição e modelagem específicas para esse tipo de dado, como eu abordo neste outro texto. No entanto, conhecendo nossos dados, com as métricas e o gráfico apresentados podemos concluir que, ainda que não esteja perfeito, nosso modelo é bom o suficiente para prever as movimentações nas estações de aluguel.
Até agora, ainda não exploramos nada além do que já conhecíamos. Então, vamos expandir a base X_test para os meses seguintes e, assim, obter uma predição que indique a movimentação até o final de 2017. Visualizamos esse resultado no gráfico a seguir.
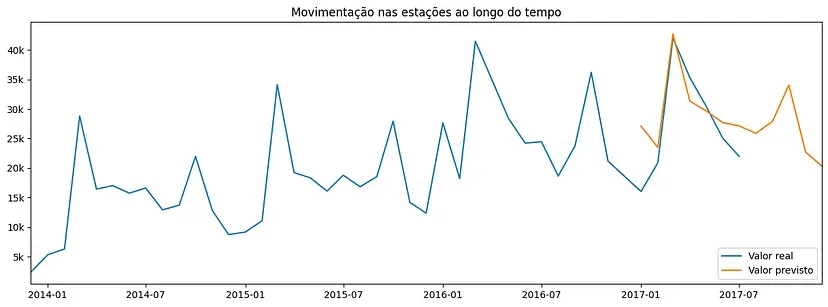
Assim, conseguimos observar o comportamento das movimentações nos próximos meses, que claramente segue o comportamento sazonal dos dados antigos.
Além desse resultado visual, com os dados da predição nos meses seguintes, temos que o valor absoluto das movimentações entre agosto e dezembro de 2017 deve ser da ordem de 130 mil, somente nas estações que concentram 80% do movimento.
Transformando dados em informações
Com o que trabalhamos até agora, podemos tirar algumas conclusões relevantes para o planejamento da instalação dos painéis eletrônicos:
- O movimento se concentra no horário da tarde. Então o aluguel do espaço publicitário pode ter um preço mais elevado entre 12h-18h.
- Na primavera, as estações de bicicleta são mais movimentadas. O espaço publicitário também pode ser alugado por um preço mais alto nessa época do ano.
- Temos uma lista das estações de bicicleta ordenadas pela quantidade de movimentações. A instalação dos painéis pode ser feita nessa ordem para garantir um retorno financeiro mais rápido. Além disso, com a instalação feita em cerca de metade das estações, já temos um ótimo alcance do total de movimentações.
- Sabemos que, nos próximos 5 meses, a previsão é de cerca de 130 mil movimentações nas estações de aluguel que concentram 80% do movimento. Para contratar empresas que utilizarão o espaço publicitário, essa informação é bastante relevante.
Com isso, concluímos nossa análise sobre os alugueis de bicicleta. O código completo utilizado no desenvolvimento pode ser acessado aqui.
Se quiser saber mais sobre como utilizar a tecnologia dos dados a seu favor, confira os outros posts no Medium da BIX Tecnologia. Ou ainda, entre em contato com o nosso time, ficaremos muito felizes em ajudar!
Escrito por Laura Fiorini






