

Poucas pessoas sabem, mas a Receita Federal disponibiliza, a cada 3 meses, em seu site uma base “pública” com informações de todas(!) as empresas do Brasil e seus respectivos sócios. Com essas informações disponíveis, você pode processar dados públicos de todas as empresas do Brasil com o Google Cloud, utilizando Storage, Dataflow e Big Query.
Esse post tem como objetivos:
- Democratizar o acesso aos dados públicos. Uma vez que a base está disponível, mas é necessário um certo esforço para conseguir de fato transformar esses dados em informações relevantes;
- Demonstrar como uma arquitetura serverless na nuvem pode ser útil para o tratamento de um grande volume de dados.
Uma pergunta que pode surgir é: Qual a utilidade de uma base dessas? Dado que a base possui todos os CNPJs, razão social, CNAE, data de abertura, capital social, endereço, telefone, nome dos sócios, etc. Eu diria que as possibilidades são infinitas. Desde análise de concorrentes pelo mesmo CNAE até prospecção de clientes B2B.
Para melhor entendimento, dividi as etapas em quatro passos que vão te ajudar a processar os dados das empresas:
- Extração
- Transformação
- Carga
- Visualização
Ao final, teremos a arquitetura abaixo:
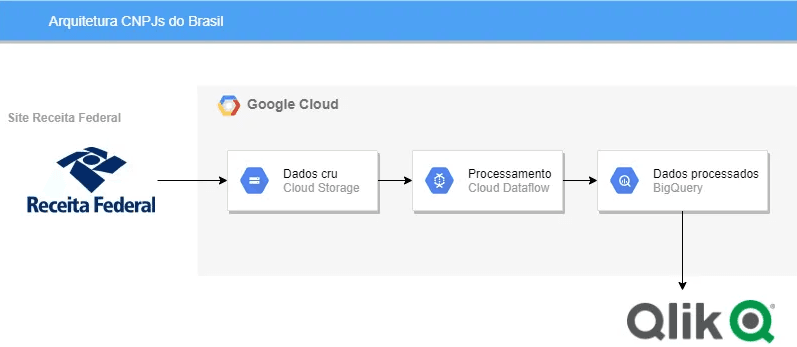
Os códigos utilizados estão no GitHub.
Processando dados públicos de todas as empresas do Brasil utilizando o Google Cloud em quatro passos:
A partir da base disponibilizada pela Receita Federal, vamos processar dados de empresas com o Google Cloud e utilizar ferramentas como Storage, Dataflow e Big Query. É possível transformar os dados em informações relevantes e perceber que a arquitetura serverless pode ser aplicada no tratamento de um grande volume de dados. Você pode aplicar essas informações em diversas áreas do seu negócio e ampliar seus resultados!
1. Extração
A primeira etapa é basicamente baixar os dados da Receita e jogá-los para dentro do Google Cloud Storage.
Para isso, utilizei uma VM Linux do Compute Engine do Google Cloud. Nessa etapa, utilizei o comando wget para baixar os arquivos, unzip para deszipar, o comando screen para deixar a VM rodando em background enquanto fazia o download e o comando gsutil cp para copiar o arquivo da VM para o Cloud Storage.
sudo apt-get install wget screen unzip -y
wget http://200.152.38.155/CNPJ/DADOS_ABERTOS_CNPJ_01.zip
unzip DADOS_ABERTOS_CNPJ_01.zip
gsutil cp K3241.K032001K.CNPJ.D01120.L00001 gs://cnpj_empresas/raw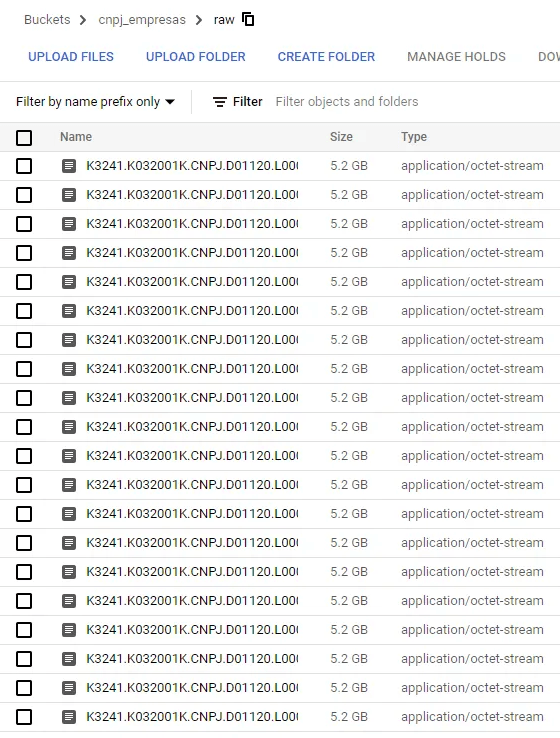
2. Transformação via Dataflow
Para o processamento de dados foi utilizado o Dataflow conheça mais aqui) do Google Cloud. Suas principais vantagens são:
- Arquitetura serverless, auto escalável e distribuída;
- Portabilidade, uma vez que desenvolve em cima do Apache Beam e pode rodar seu código fora da cloud;
- Processamento em tempo real e em bateladas (Beam = batch + stream).
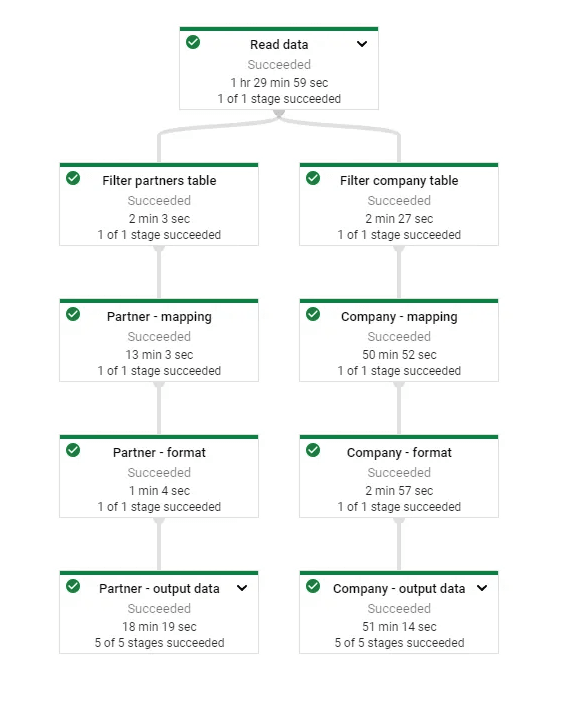
Essa é a parte mais complexa, pois é necessário destrinchar todo o dicionário de dados disponibilizado pela Receita Federal e se atentar a alguns detalhes:
- São várias tabelas concatenadas uma em cima da outra dentro do mesmo arquivo. Elas se diferenciam pelo flag ‘Tipo do registro”. Foi utilizada a tabela das empresas e dos sócios, flags 1 e 2 respectivamente.
- Os campos estão delimitados por um tamanho fixo e não por algum caracter especial como nos arquivos padrões em CSV.
- Os arquivos estão em formato de codificação iso-8859 e não utf-8. Precisei criar um novo tipo de classe Coder para tratar isso (esse link me ajudou).
- Foi necessário tratar alguns formatos de data e de texto. Nada muito diferente da rotina de um engenheiro de dados.
Todo o código utilizado pode ser encontrado no GitHub.
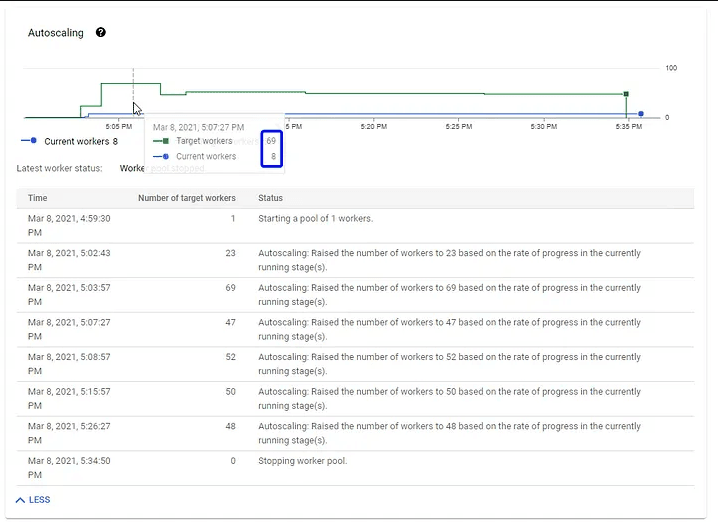
Vale observar abaixo o poder do autoscale do Dataflow sugerindo aumentar para 69 workers de maneira otimizada à medida que os dados estavam sendo processados.
3. Carga no Big Query
Os dados processados no Dataflow foram carregados no Big Query, uma ferramenta também serverless voltada para Data Warehouse em que você só paga pelo que utiliza.
Nessa etapa foram criados dois datasets. Um raw com os fatos e dimensões (os arquivos das dimensões estão no git) e um trusted com uma tabela fato unificada das empresas e sócios e filtrada apenas com as empresas ativas.
A tabela final possui quase 9GB e 22 milhões de linhas. Vale notar também que a tabela está particionada e clusterizada para ganhos de performance e redução de custos. Veja mais detalhes aqui.
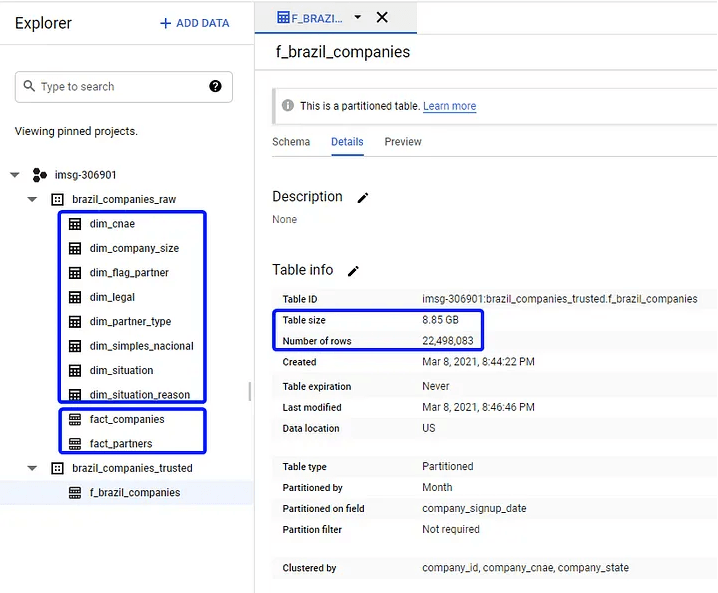
Antes de carregar a tabela para visualização, nada mais justo que fazer um sanity check para validar os dados. Busquei pelo CNPJ da BIX Tecnologia para ver o que o Big Query retorna.
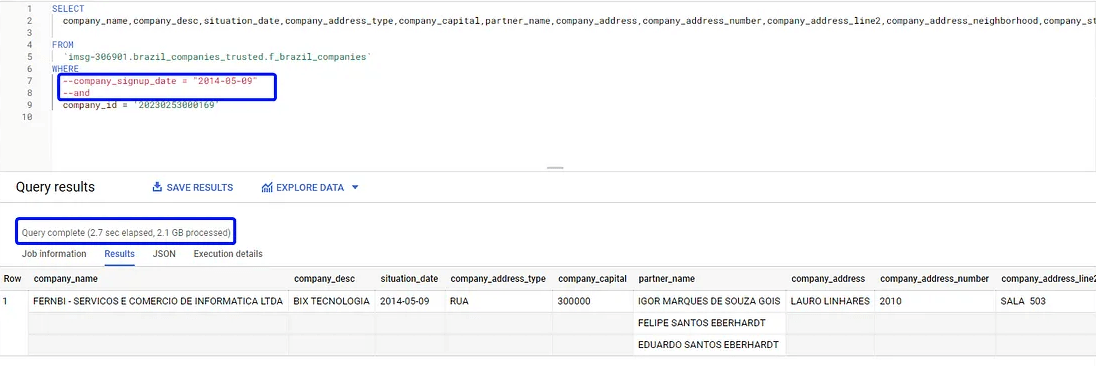
Legal né? Em uma tabela de 9GB com 22 milhões de registros, o Big Query precisou processar 2,1GB e em menos de 3 segundos retornou as informações de uma única empresa.
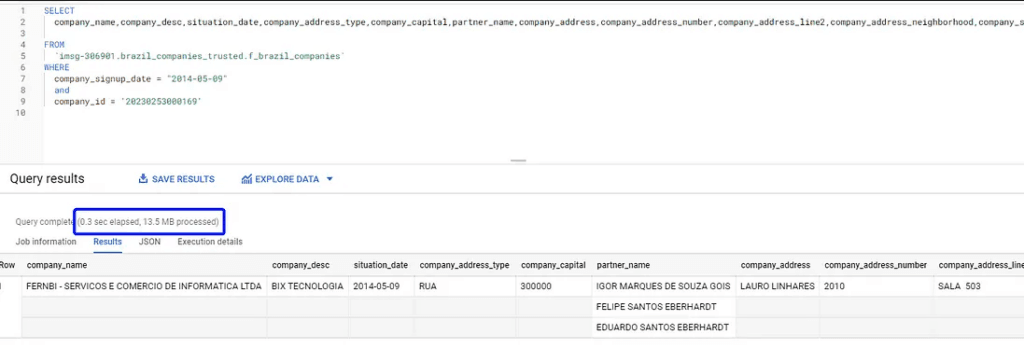
Será que tem como melhorar isso? Vale fazer um teste de performance comparando uma consulta utilizando um filtro com campo particionado, que nesse caso é a data de abertura.
Note que a consulta com o filtro particionado levou apenas 0,3 segundos e apenas 13,5 MB para retornar os mesmos dados (isso não foi cache da consulta anterior!). Com isso, foi possível reduzir custos e melhorar a performance – bem vindo ao dia-a-dia da BIX!
Falando em custo, todo o processamento custou por volta de R$7 e o armazenamento no Storage e no Big Query de todos os arquivos e tabelas custam míseros R$0,52 centavos por dia.
4. Visualização no Qlik Sense
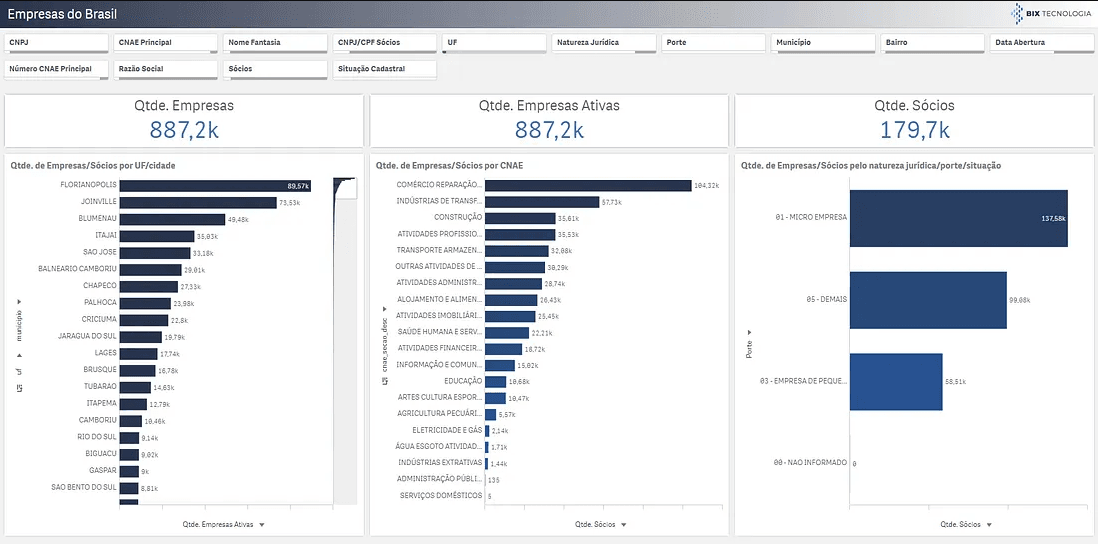
Uma vez que os dados estão todos organizadinhos no Big Query, fica fácil jogar para qualquer ferramenta de visualização para fazer as análises e descobertas nos dados.
Nesse caso utilizei o Qlik Sense, que é bem robusto para grande volume de dados, já tem conexão nativa com o Big Query e é um dos melhores para realizar data discovery.
Aqui consigo buscar informações de todas as empresas do Brasil pelo CNPJ, pelo nome dos sócios, pelo CNAE, pelo tamanho, pela cidade ou endereço. Enfim, as possibilidades são infinitas!
Como próximos passos poderia, por exemplo, adicionar uma base de tamanho da população e verificar qual cidade tem menos empresas com o mesmo CNAE da BIX Tecnologia per capita e definir onde será nossa próxima filial! 😉
Conclusões sobre o processamento de dados públicos
Processar dados públicos de todas as empresas do Brasil com o Google Cloud ficou mais fácil, né? Utilizando a base da Receita Federal, foi possível extrair os dados e começar a trabalhar no Google Cloud Storage. Para o processamento, o Dataflow apresentou vantagens como sua arquitetura serverless, portabilidade e a possibilidade de um processamento em tempo real e em bateladas. Depois, os dados foram carregados no Big Query e otimizados através de um teste de performance. Por fim, as análises e descobertas foram feitas no Qlik Sense, uma das melhores plataformas para realizar data discovery. O que retiramos dessa experiência?
- Os dados são públicos, mas são disponibilizados em um emaranhado de arquivos e formatos que nem todo mundo consegue de fato acessar.
- Arquiteturas serverless na nuvem são bem poderosas e acessíveis para processamento de grande volume de dados.
- Sempre é possível otimizar o pipeline de dados, seja em performance ou custo.
Nesse post, você viu como processar dados com ferramentas sofisticadas e poderosas para utilizar nas mais diversas áreas. Esse é o tipo de case que a BIX desenvolve, somos uma consultoria de dados focada em resultados e negócios!
Quer saber mais sobre como aplicar dados na sua empresa? Entre em contato conosco! Vamos buscar a melhor maneira de utilizar os dados para alavancar seus resultados!
*Artigo por Igor Gois.






