

Atualizado em 30 de agosto de 2024
Criar soluções inovadoras é essencial para manter a sua empresa ou projeto competitivos, uma das melhores formas de fazer isso é utilizando os dados. Seja para criação de uma análise preditiva, Processamento de Linguagem Natural ou reconhecimento de imagem, iremos precisar de uma equipe super completa para começar a implementação, certo?!
Na verdade, não necessariamente! Neste artigo, iremos te guiar no desenvolvimento de uma solução simples de Análise Sentimental, utilizando a Google Vertex AI. Com essa ferramenta, é possível desenvolver soluções de Machine Learning de ponta a ponta, desde a ETL até a previsão de novos dados, utilizando o mínimo de código possível! Continue a leitura e saiba mais.
O que é a Google Vertex AI?
A Google Vertex AI é uma plataforma unificada e totalmente gerenciada que centraliza todas as ferramentas para desenvolvimento de Inteligência Artificial e Machine Learning do Google Cloud Platform (GCP). Com ela, é possível criar pipelines completas, desde a preparação dos dados (ETL) até a implantação de modelos, suportando diversos formatos, como texto, imagens, vídeos e dados tabulares. Sua flexibilidade permite utilizar tanto modelos predefinidos via AutoML quanto códigos customizados de treinamento. Isso torna o processo de experimentação e melhoria contínua mais ágil e simples.
Além disso, a Google Vertex AI oferece acesso a modelos de IA generativa avançados, como o Gemini, que combina diferentes tipos de dados para gerar saídas complexas, desde texto até informações extraídas de imagens. Há também o Gemma, outra linha de modelos desenvolvidos a partir das mesmas tecnologias de ponta. Com essas ferramentas, os desenvolvedores podem criar soluções de IA inovadoras para diversos casos de uso.
O projeto que faremos hoje vai utilizar o AutoML para definir o modelo de treinamento, sendo a escolha ideal para pôr um MVP (Mínimo Produto Viável) no ar e começar a avaliar se o projeto funciona. Com o tempo, após validação do MVP, será necessário aprimorar a IA. O melhor de tudo é que, como a Vertex AI é super flexível, o processo de experimentação e melhoria da pipeline é bem mais simples!
Análise sentimental com a Google Vertex AI
Sem mais delongas, vamos ao assunto deste artigo. Imagine que seu objetivo é ajudar pessoas que enfrentam dificuldades emocionais. Você percebe que pode identificar quem precisa de apoio analisando as postagens dessas pessoas no X (antigo Twitter). Como profissional de dados qualificado, você tem uma técnica eficaz para ajudá-las. O desafio agora é encontrar essas pessoas!
Se você tentasse identificar esses usuários apenas lendo tweets manualmente, o processo seria muito lento e, provavelmente, inviável. Mas, e se você pudesse usar um “filtro” para passar por milhões de comentários e só ler aqueles com alta probabilidade de indicar que alguém está passando por um momento difícil? Bem mais eficiente, certo?
Por isso, para reconhecer essas pessoas de forma rápida e precisa, vamos usar uma IA treinada com uma lista de textos previamente classificados. Essa IA avaliará os posts de um usuário e determinará se eles podem indicar um comportamento depressivo.
Para isso, utilizaremos uma tabela disponibilizada no Kaggle neste link.
Observação importante: apesar de ser possível detectar padrões de comportamento utilizando Machine Learning, a identificação e diagnóstico de doenças mentais devem ser feitos por um profissional certificado da área da saúde.
Passo a passo da análise sentimental com a Google Vertex AI
Estas serão todas as etapas necessárias para construir uma solução de Machine Learning utilizando a Google Vertex AI:
- Etapa 0: Configuração do projeto e ambiente
- Etapa 1: Acessando os dados
- Etapa 2: ‘Jogando’ os dados para o Cloud Storage
- Etapa 3: Criar um conjunto de dados
- Etapa 4: Treinando o modelo
- Etapa 5: Avaliação do modelo
- Etapa 6: Deploy
- Etapa 7: Fazer previsões
Passo #00: Configuração do projeto e ambiente
Para desenvolver essa análise sentimental, você precisa ter acesso à Google Cloud Platform (GCP) com uma conta que possua créditos disponíveis. Se você ainda não tem uma conta, pode criar uma gratuitamente e receber $300 em créditos para explorar as ferramentas da GCP.
Para configurar o seu ambiente e habilitar a API da Google Vertex AI, siga o tutorial disponibilizado pelo Google.
Passo #01: Obtenha acesso aos dados
Você pode baixar os dados que utilizaremos neste exemplo por meio deste link do Kaggle.
Precisaremos fazer algumas pequenas modificações na estrutura dos dados, de forma que ele esteja adequado para ser usado no AutoML. Você pode ler mais sobre a formatação, de acordo com o tipo de projeto, neste link.
Passo #02. ‘Jogue’ os dados para o Cloud Storage
Para armazenar nossos dados na Cloud, e então utilizá-los no treinamento do modelo, precisamos criar um Bucket na Cloud Store. Como prometemos fazer o processo com o mínimo de código possível, utilizaremos apenas o console da GCP.
- Acesse o Navegador do Cloud Storage;
- Clique em Criar intervalo;

- Preencha as informações conforme sua necessidade. Para mais informações sobre cada um dos campos, acesse este link.
Uma vez criado o Bucket, abra-o e clique em “Fazer Upload de Arquivos“. Selecione o arquivo ‘sentiment_tweets_new.csv’, contendo os dados que iremos usar.
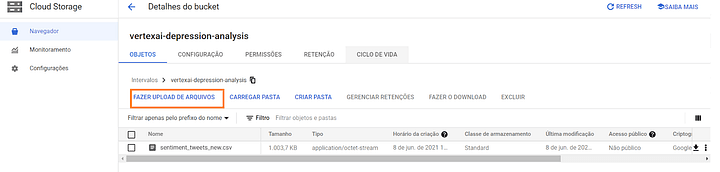
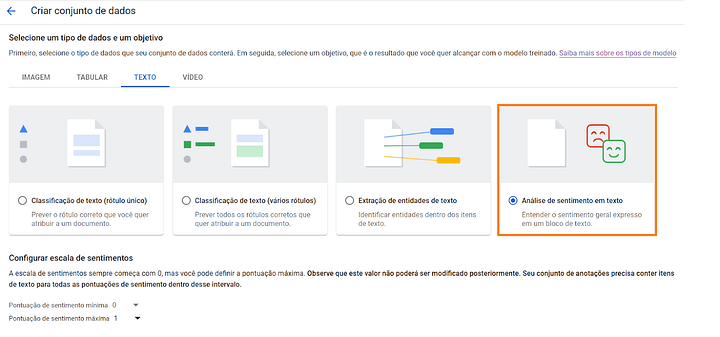
Passo #03: Crie um conjunto de dados
Agora, montaremos o nosso conjunto de dados. É aqui que definiremos o tipo de análise que será utilizada. Nesse caso, faremos uma análise de sentimento em texto.
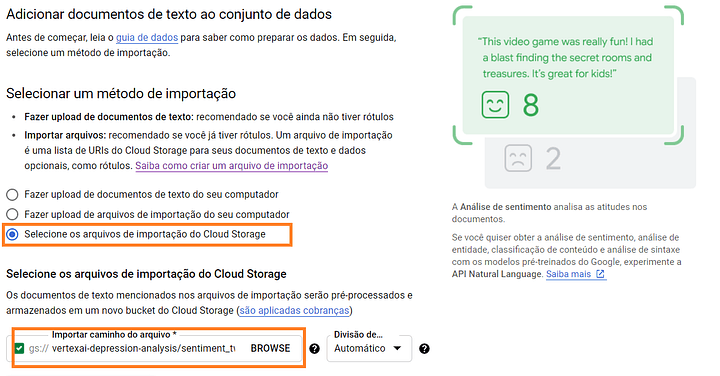
Na hora de definir a importação dos dados, iremos selecionar o arquivo .csv presente no Bucket que criado no início do projeto.
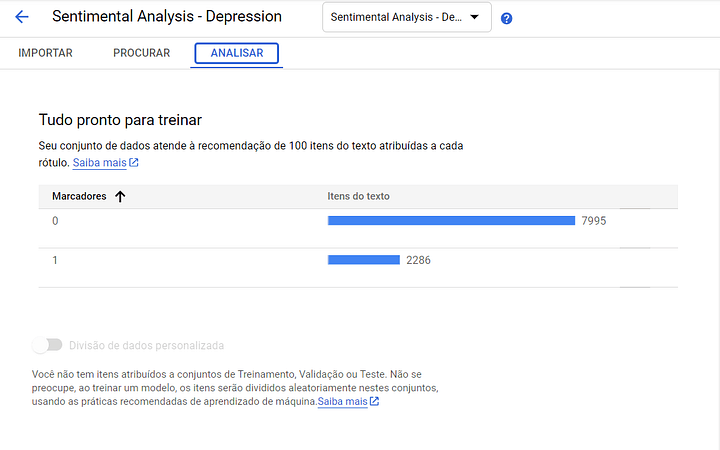
Uma vez montado o conjunto de dados, é muito importante avaliarmos a dispersão deles e como são constituídos. Na aba “Analisar”, é possível ter a visão de todas as variáveis que constituiem o seu modelo de dados, inclusive aquelas que serão preditas.
Passo #04: Treine o modelo
Agora que já temos o conjunto de dados criado, podemos treinar o nosso modelo. Para isso, clicamos em “Treinar Novo Modelo”.
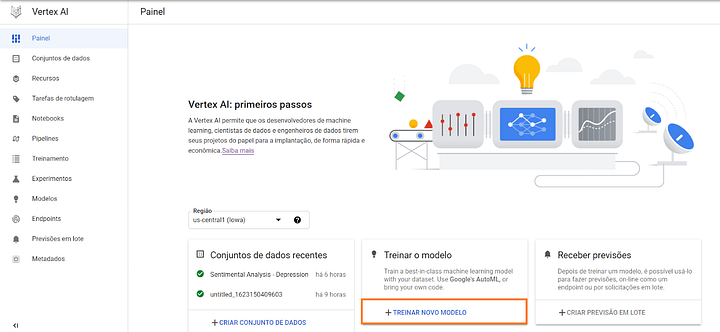
Como optamos por desenvolver um projeto com o mínimo de código possível, iremos utilizar o AutoML para o treinamento.
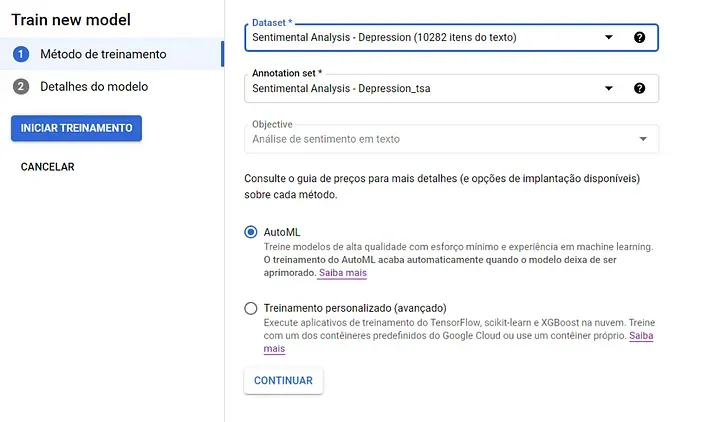
Por fim, basta definir a quantidade de dados que serão destinados para treinamento, validação e teste dos resultados. Neste projeto, usamos os valores padrões sugeridos. Para treinar o modelo, basta clicar em “Iniciar Treinamento” e esperar até que o processo seja concluído!
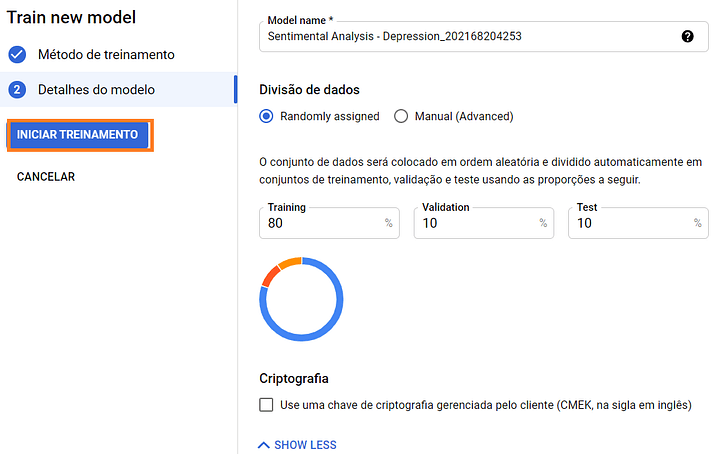
Passo #05: Avalie o modelo
Quando o treinamento estiver finalizado, podemos avaliar a performance resultante. Para isso, basta abrir a aba “Modelos” e clicar naquele que acabamos de treinar.
Na aba “Avaliar”, já conseguimos visualizar a Precisão:
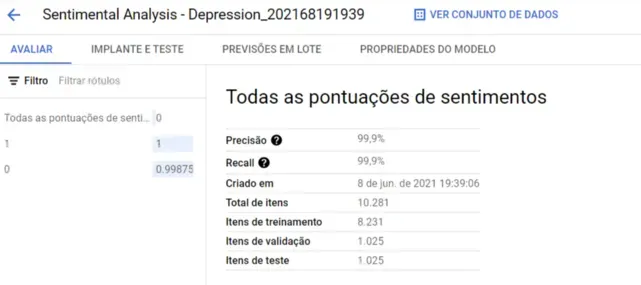
Mas, o mais importante é considerar os valores apresentados na matriz de confusão. Nela, vemos os valores previstos corretamente e incorretamente para cada rótulo definido.
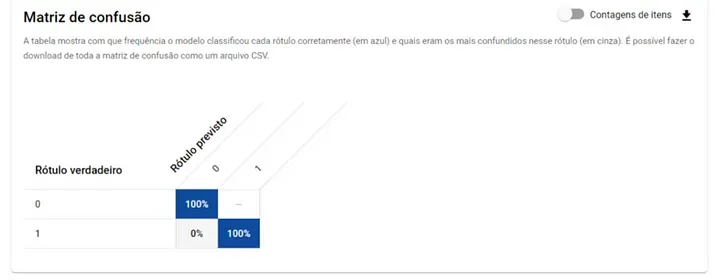
Para entender a importância da matriz de confusão, considere o seguinte exemplo: uma IA foi desenvolvida para detectar se uma pessoa tem uma certa doença. No grupo de estudo, apenas 1% das pessoas realmente possuem essa condição. Após o treinamento, o modelo alcança 99% de precisão. Isso parece bom, certo? Mas, será que é mesmo? Imagine que um médico, sem examinar ninguém, simplesmente afirma que nenhuma das pessoas tem a doença. Qual seria a precisão desse médico? Também 99%.
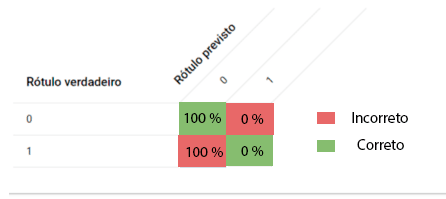
Em outras palavras, o médico de “olhos vendados”, apesar de ter 99% de precisão, não conseguiu identificar corretamente nenhum paciente com a doença. Isso ocorre pois estamos focando apenas no desempenho geral, sem considerar os resultados para cada categoria específica, como “Ter a doença” e “Não ter a doença”.
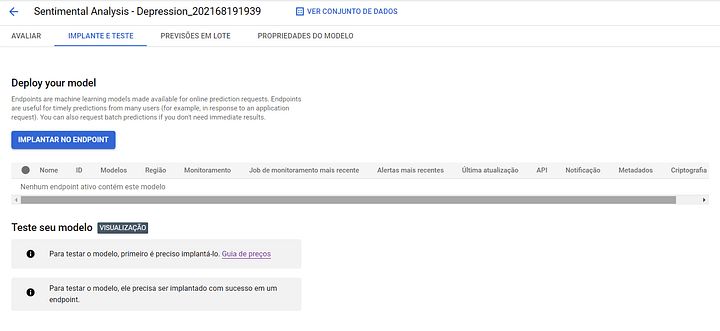
Passo #06: Faça o deploy
Depois de ter avaliado o seu modelo, para fazer o deploy, basta trocar de aba para “Implante e Teste”.
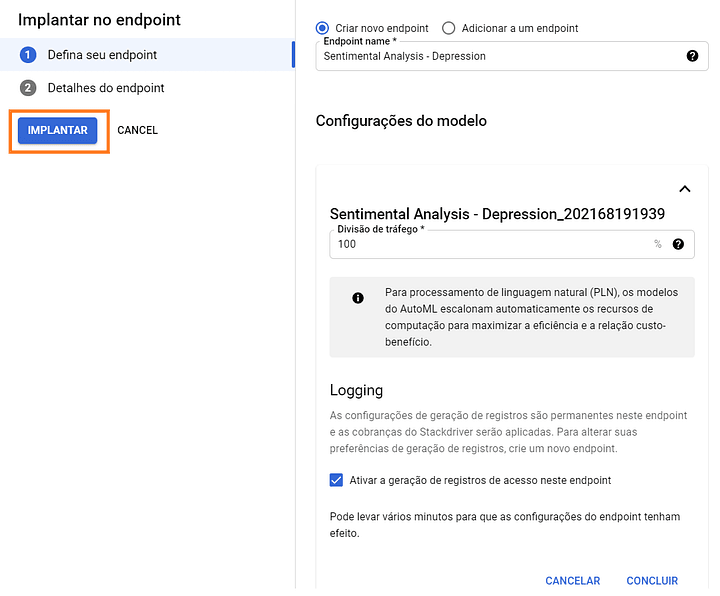
Para criar o Endpoint, precisamos apenas definir o nome. O tráfego fica em 100% pois temos apenas um modelo. Em casos mais avançados, podemos dividir os tráfegos entre mais de um modelo, de forma que seja possível a validação de novas soluções.
Passo #07: Faça previsões
Pronto! Temos nosso modelo treinado e preparado para receber novas previsões. Antes de sairmos para fazer a conexão de alguma aplicação ao nosso Endpoint, vamos fazer um teste.
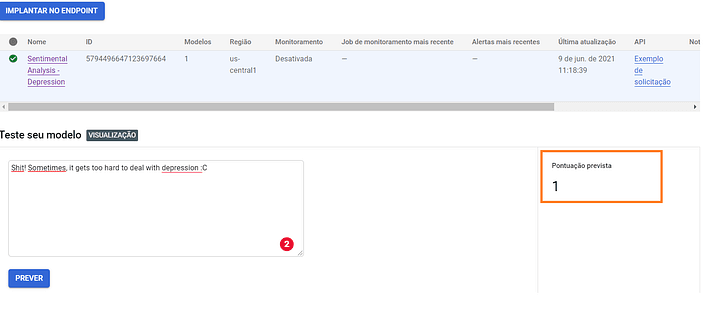
Parece que está funcionando!!
Agora, iremos testar o nosso Endpoint com uma conexão utilizando Python. Para que essa etapa funcione, você deve ter autenticado as credenciais do seu projeto. Para saber mais sobre, leia aqui.
Utilizaremos o seguinte código exemplo, sugerido pela Google, para acessar nossa API:
# Copyright 2020 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# [START aiplatform_predict_text_sentiment_analysis_sample]
from google.cloud import aiplatform
from google.cloud.aiplatform.gapic.schema import predict
from google.protobuf import json_format
from google.protobuf.struct_pb2 import Value
def predict_text_sentiment_analysis_sample(
project: str,
endpoint_id: str,
content: str,
location: str = "us-central1",
api_endpoint: str = "us-central1-aiplatform.googleapis.com",
):
# The AI Platform services require regional API endpoints.
client_options = {"api_endpoint": api_endpoint}
# Initialize client that will be used to create and send requests.
# This client only needs to be created once, and can be reused for multiple requests.
client = aiplatform.gapic.PredictionServiceClient(client_options=client_options)
instance = predict.instance.TextSentimentPredictionInstance(
content=content,
).to_value()
instances = [instance]
parameters_dict = {}
parameters = json_format.ParseDict(parameters_dict, Value())
endpoint = client.endpoint_path(
project=project, location=location, endpoint=endpoint_id
)
response = client.predict(
endpoint=endpoint, instances=instances, parameters=parameters
)
print("response")
print(" deployed_model_id:", response.deployed_model_id)
# See gs://google-cloud-aiplatform/schema/predict/prediction/text_sentiment.yaml for the format of the predictions.
predictions = response.predictions
for prediction in predictions:
print(" prediction:", dict(prediction))
# [END aiplatform_predict_text_sentiment_analysis_sample]
predict_text_sentiment_analysis_sample(
project = 'NOME DO PROJETO',
endpoint_id = 'ENDPOINT-ID',
c,
location = 'us-central1', #Lozalização, por padrão, é us-central1. Modificar de acordo com o que você definiu na Endpoint
api_endpoint = "us-central1-aiplatform.googleapis.com"
)E quando a sua base não é bem preparada?
Nesse projeto, utilizamos um banco de dados público, tendo em vista que é somente um exemplo. Observe o que pode acontecer quando sua base não é bem preparada:
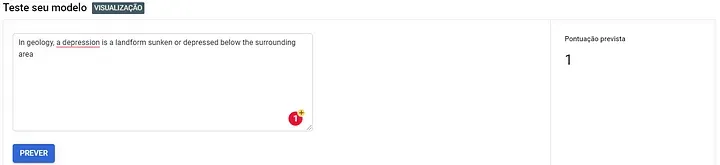
Nesse caso, o termo depressão foi usado em um contexto de geologia; mesmo assim, foi categorizado como o estado emocional.
Este projeto foi desenvolvido com o objetivo de demonstrar o desenvolvimento de uma solução na Google Vertex AI. Em um projeto real, deve-se atentar para a qualidade dos dados. O seu conjunto de dados deve abranger todos os casos que seu negócio atinge, e deve ter uma quantidade razoável de linhas para cada um deles.
Explore o potencial da Google Vertex AI com a BIX Tecnologia!
Se você está pronto para transformar dados em insights poderosos, a BIX Tecnologia pode te ajudar a explorar o potencial da Google Vertex AI. Desde análise sentimental até detecção de fraudes e recomendações personalizadas, oferecemos o suporte necessário para criar soluções de Machine Learning de ponta a ponta.
Entre em contato conosco e vamos dar o primeiro passo no seu próximo projeto de IA juntos!

Escrito por Vittorio Girardi






